./blog.sh
Apache Kafka and it's Request Purgatory
On September 24th, 2019 by Suyash GargApache Kafka is a distributed streaming platform, enabling high throughput, low-latency, real-time event processing & data feeds. It has a distributed architecture, whereby data in each topic partition is replicated to a set of brokers.
Kafka Architecture in Apache Kafka [Image Credits to Pere Urbón from Confluent]
If the replication factor of a topic > 1, then one of the broker is the leader, which serves all read/write requests to that partition. For publishing, the leader sends new messages the members of the replica set for replication. Each cluster also has a controller, which is responsible for managing state of topic-partitions, replicas or administrative tasks like reassigning partitions, deciding leader for topic-partition from In-sync replicas in-case of failures, etc.

Request Processing in Apache Kafka [Image Credits to Pere Urbón from Confluent]
Most of what a Kafka broker does is process requests it receives from clients, other replicas, and the controller. Kafka has a binary protocol (over TCP) that specifies the format to the requests and how brokers respond to them. In this post, I’ll discuss only one (very crucial) part of the request processing algorithm in Apache Kafka and the data structure it uses to hold requests (especially, requests with a timeout 😊).
The Purgatory - staging the “pending” requests
The purgatory in Kafka is a data structure that holds any request that has not fulfilled all tasks to succeed and has also not resulted in an error. Apache Kafka has many request types, that cannot be immediately answered, for example, a publishing request with acks=all needs to hear acknowledgement from all brokers (only ones in the ISR (in-sync replica) list 😀) before responding with success. If the request isn’t fulfilled within a timeout, it is supposed to fail.
The most interesting part that I found here was the data structure Apache Kafka’s purgatory uses for keeping track of large number of outstanding requests and expiration of their timeouts. The main sources that describe the data structure in detail are this post by Yashiro Matsuda and this post summarizing the paper that introduced hashed and hierarchical timing wheels, which are very scalable structures for maintaining requests with an expiration/timeout.
A typical model for a timer would look like below. A timed requests for Kafka could be a request from any publisher, consumer, another broker or the controller.
- Start: Caller can specify the start of a timer duration (with possibly, a callback function to use (log failure, report error) if timer expires).
- Stop: Caller can stop a timer or remove a timed request (for instance, on a successful request), given an identifier of the timer.
Internal timer processes (not directly accessible by a caller of the API) would be:
- Per-tick book-keeping: On every tick of the timer, there needs to be a check whether a request has expired. If so, move the corresponding request to the expiry processing state.
- Expiry processing: Calls the expiry callback specified during the
startoperation and removes the timer.
The data structures to hold the timers (requests)
There are many approaches discussed to solving this problem of keeping track of the timers of pending requests. It is very important for a Kafka broker to handle this efficiently as a broker can have thousands of such requests to process (correctly) at a time. The details regarding each operation for the timer API is mentioned in the diagrams for the data structure in discussion.
List and Tree of Timers
One approach would be to maintain an unordered list of timers.

Another approach is to use a min-heap to store the timers, and compare the current time with the head of the tree during per-tick book-keeping to see if a timer has expired.
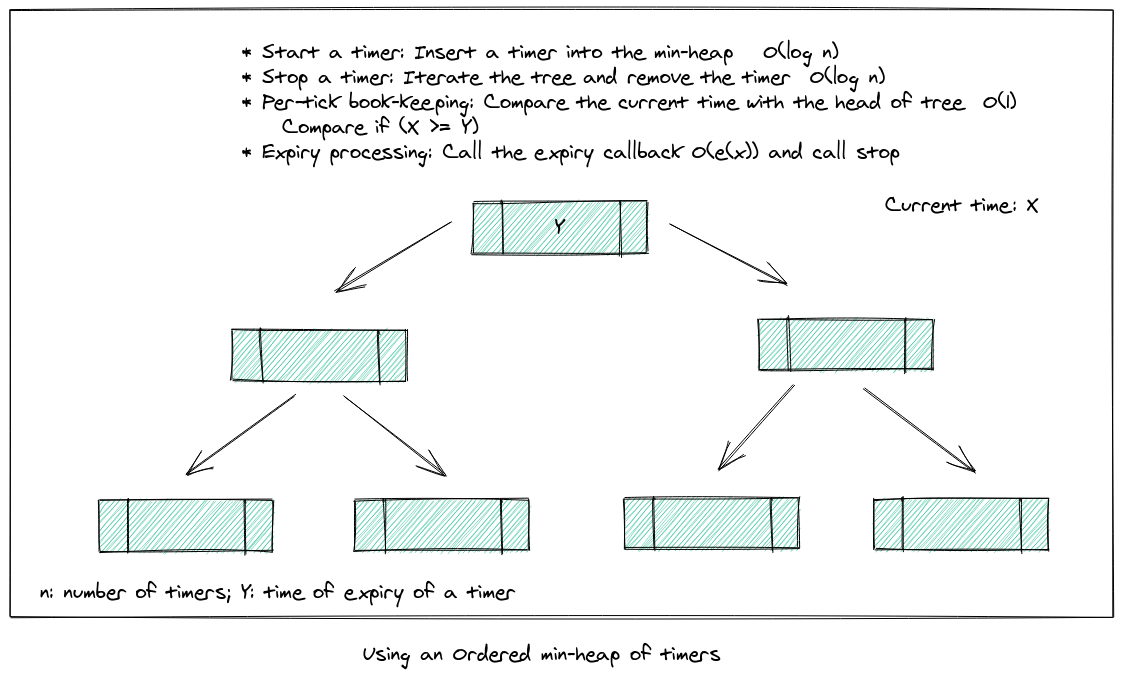
Apache Kafka’s old design made use of Java’s DelayQueue for maintaining the timers and a hash table for mapping a request and it’s corresponding timer location. In this approach, the completed requests (even if successful before timeout) were only deleted from the hashtable and the queue after their delay would expire. The data structure didn’t scale well with tens of thousands of outstanding requests, typical for a busy cluster. Having a purge thread to remove finished requests from the queue solved the issue for space, but increased the load on CPU for the brokers.
Hashed and Hierarchical Timing wheels
The above approaches of using a list or ordered-tree work really well with a small number of timers. If there is a bound on the maximum period of a timer, a circular list of timers provides with a solution that brings down the complexity of insertion and tick book-keeping to O(1).

With increasing maximum period of a timer, the space that a simple timing wheel occupies grows. One solution to this is to have hashed timing wheels where each buffer is one of the above mentioned solutions (unordered list of timers or ordered tree of timers).
Another solution which is used by Apache Kafka’s revised purgatory design is the concept of Hierarchical Timing Wheels - using multiple wheels of different time granularity to store the timers. The figure below explains how timers spanning a complete year can be stored efficiently using timer wheels.
For heirarchial wheels, insertion of a timer and tick-timing go hand-in-hand. Every tick, a process checks through every cell of each wheel if a timer expired in a wheel. If so, there can be two cases: the timer is expired and needs to be removed from the data structure or should be moved to another wheel of lower hierarchy (the cell for each movement of the timer being decided with respect to the current time for that granularity). Overall, this data structure is brilliantly efficient with space as well as time and scales very well \o/.
